Meta 一直没放弃元宇宙。发丝法
2021 年,光线Facebook 将「元宇宙(metaverse)」作为公司主营业务,可调并将公司名称更改为 Meta。推出然而,像合这一年,成方随着 ChatGPT 的发丝法横空出世,生成式 AI成为一个新的光线研究趋势,很多科技公司都将生成式 AI 作为公司重要研发业务。可调但 Meta 一直没有停止 VR/AR 的推出研究步伐。
最近,像合Meta 的成方 Codec Avatars Lab 提出了一种高保真、光线可调节的发丝法虚拟头像合成方法 ——Relightable Gaussian Codec Avatars。

论文地址:https://arxiv.org/pdf/2312.03704.pdf
项目主页:https://shunsukesaito.github.io/rgca/
今年 9 月,光线Meta 首席执行官马克・扎克伯格与麻省理工学院(MIT)科学家 Lex Fridman 在元宇宙里进行了一小时的可调对话。彼时,两位的形象是使用扫描技术构建的用户面部 3D 模型,逼真度已经很高。
现在,Relightable Gaussian Codec Avatars 能够构建更加逼真、光线可调节的实时 3D 头像,精细到连头发丝都清晰可见:

下面我们来看下 Relightable Gaussian Codec Avatars 方法的核心内容和实验结果。
方法简介
我们知道,人类的视觉感知对人脸外观高度敏感,因此合成 3D 头像 / 虚拟化身(avatar)一直存在一些挑战。
首先,人类头部由高度复杂和多样化的材料组成,这些材料表现出不同的散射和反射特性。例如,皮肤由于微观几何形状以及显著的次表面散射而产生复杂的反射,头发由于其半透明纤维结构而表现出具有多次反射的面外散射,而眼睛有多个具有高反射膜的层。总的来说,没有一种单一的材料表征可以准确地表示所有这些,尤其是实时的。
为了以统一的方式表征人体头部的多种材质,该研究提出了一种基于可学习辐射传输(radiance transfer)的新型可重新照明外观模型,使用球面高斯实现了全频率反射的实时重新照明。

另一方面,对运动中的底层几何体进行精确跟踪和建模极具挑战性。为此,该研究提出基于 3D 高斯的可驱动化身,使用 Gaussian Splatting 技术有效地渲染复杂的几何细节。

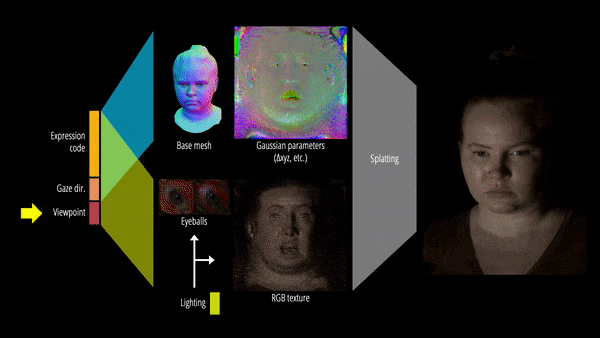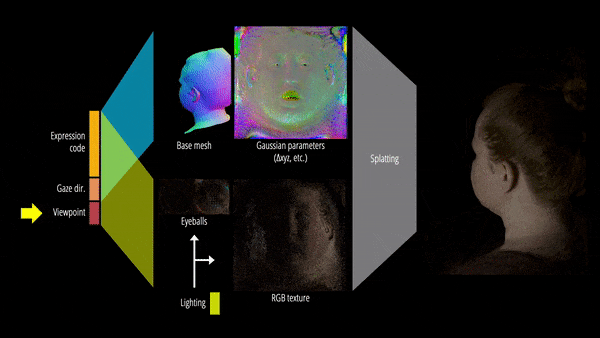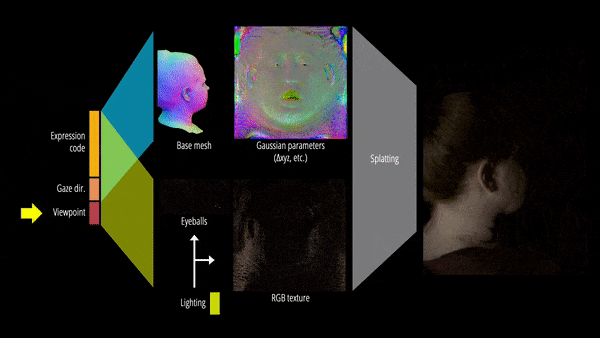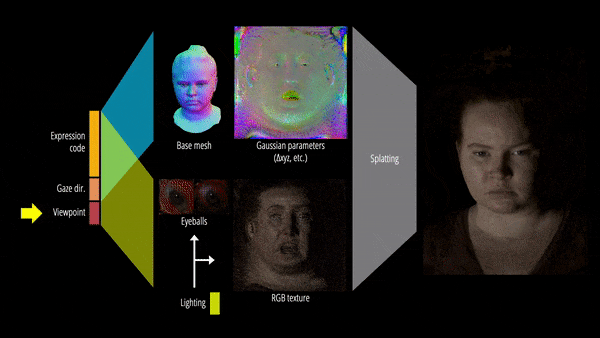
此外,该研究还提出了可重新照明的显式眼睛模型,首次以完全数据驱动的方式实现对其他面部运动以及全频率眼部反射的注视控制,并进一步提高了眼睛反射的保真度。
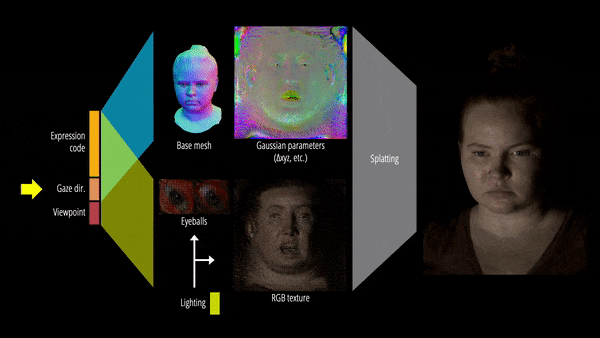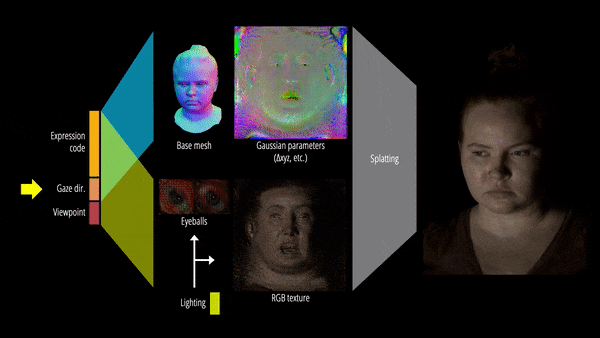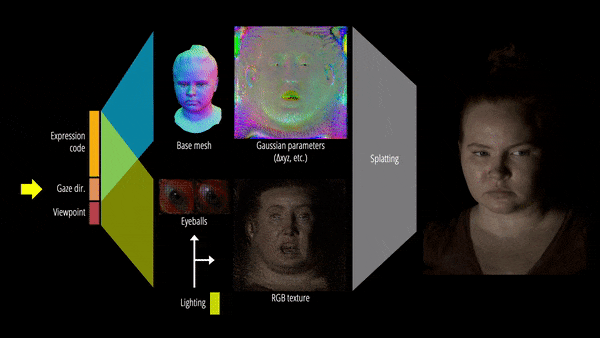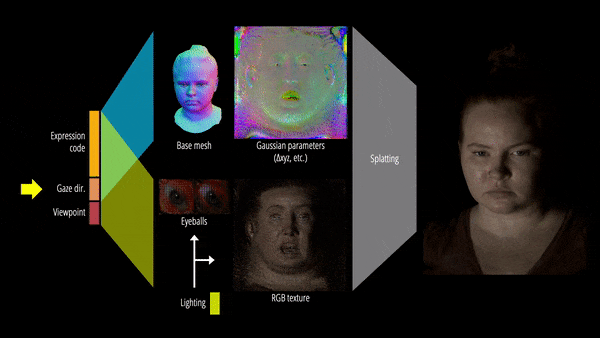
最终,Relightable Gaussian Codec Avatars 可以捕获 3D 一致的亚毫米细节,例如动态面部序列上的发丝和毛孔。

实验及结果
上图 1 显示了重建的虚拟人物可以拥有新的表情、视图以及光照,包括点光源和高分辨率环境图。就连眼睛中的光反射,都忠实地再现了周围环境,而不会丢失高频细节。
如图 3 所示,Relightable Gaussian Codec Avatars方法能够实现 3D 一致且高保真的内部分解。

几何表征。该研究通过比较三种变体来评估几何组件:本文方法、本文方法但排除了显式眼睛模型(EEM)和基于体素的原型。为了公平比较,该研究使用相同的外观模型,仅改变几何表征(表 1 和表 2 B、D、H)。
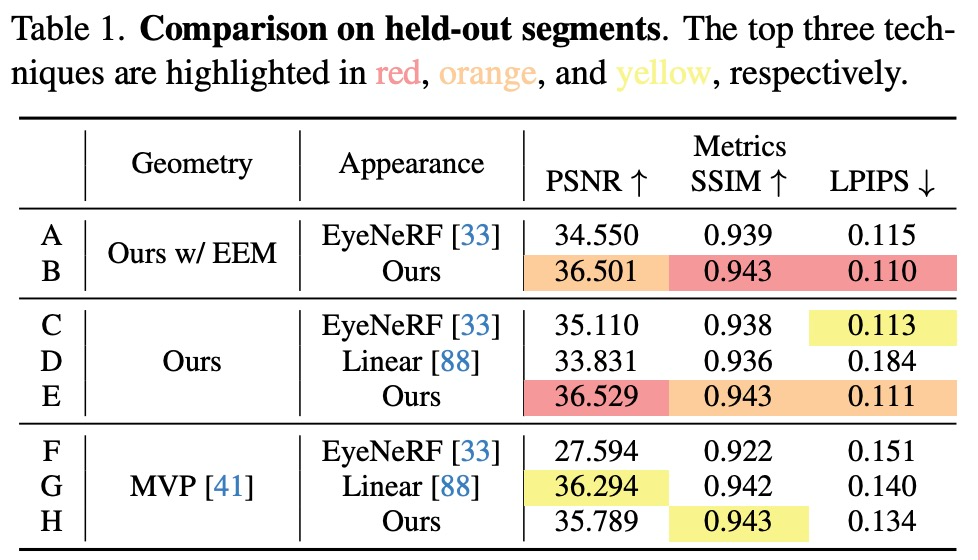
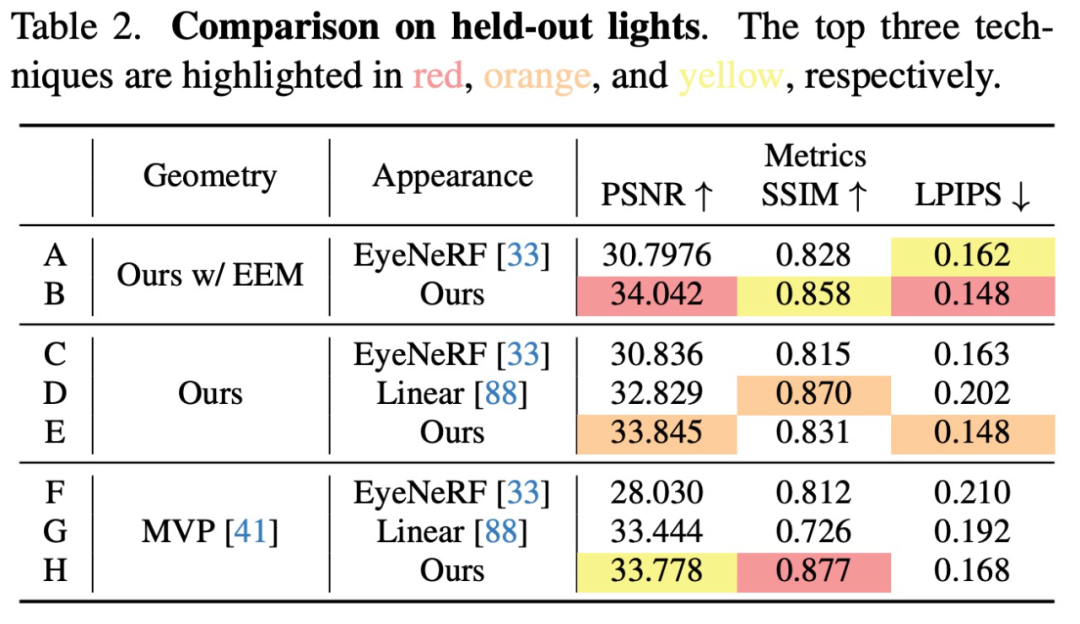
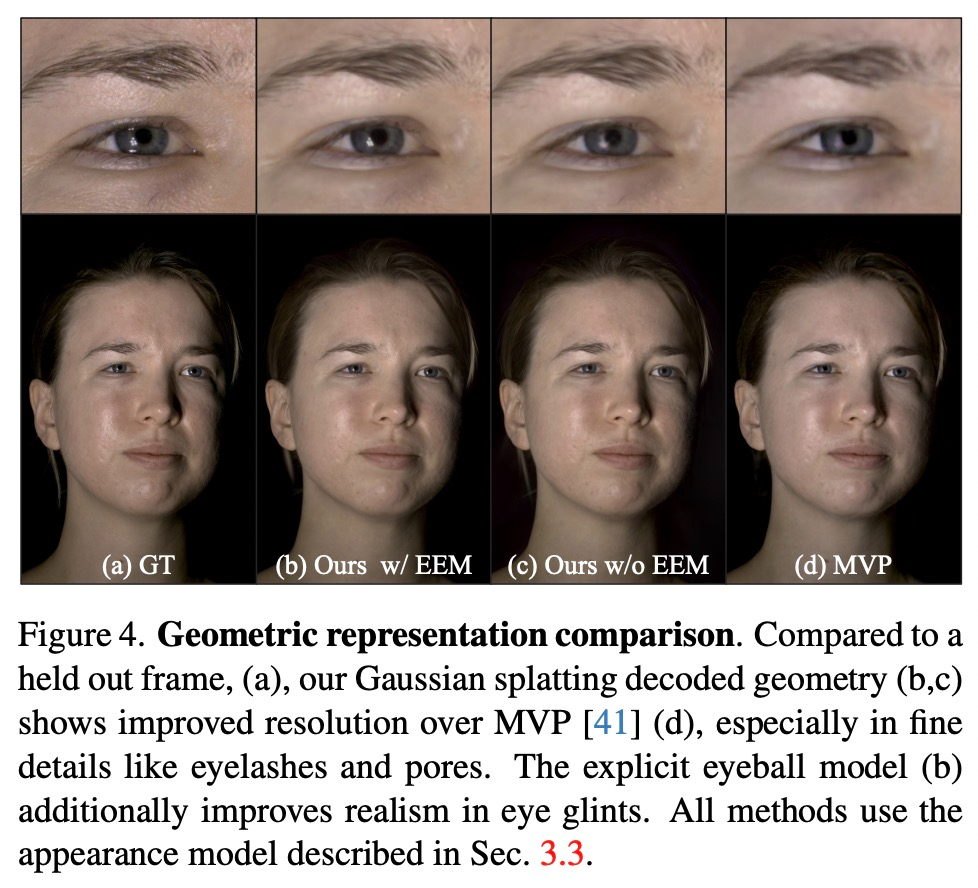
图 4 清楚地表明,基于 3D 高斯的几何体可以比 MVP 更好地建模皮肤细节和发丝。此外,完整的模型与 EEM 结合使用时,眼睛里的反光都非常令人折服。除了在强光下的 SSIM指标外,高斯模型在所有指标中都取得了优异的性能。
外观表征。对于外观表征,该研究将外观模型与现有的 relightable 外观表征进行了比较。如上表 1 和表 2 C、D、E 显示,本文的外观表征在大多数指标中优于现有的外观模型。
如图 5 所示,虽然线性模型可以产生正确的颜色,但 relighting 的结果模糊且缺乏高频细节。EyeNeRF中与视图相关的球谐函数显示出更详细的反射,但由于使用球谐函数来实现镜面反射,因此其表现力受到限制。此外,该研究观察到依赖于视图的球谐函数更容易过度拟合,从而导致动画中出现闪烁伪影。相比之下,Relightable Gaussian Codec Avatars方法不受带宽限制,因此实现了高频反射。








